
I worked with the Netflix team to create a data model they could use to describe shots, objects, and blocks used to create sizzle reels, trailers, and more. The project that this model supported was made public in November 2023.
The original article published on November 6, 2023 can be found here. As it’s under the Medium banner and may be blocked by a log-in, here is the text:
Introduction
Today we’re going to take a look at the behind the scenes technology behind how Netflix creates great trailers, Instagram reels, video shorts and other promotional videos.
Suppose you’re trying to create the trailer for the action thriller The Gray Man, and you know you want to use a shot of a car exploding. You don’t know if that shot exists or where it is in the film, and you have to look for it it by scrubbing through the whole film.
Or suppose it’s Christmas, and you want to create a great Instagram piece out all the best scenes across Netflix films of people shouting “Merry Christmas”! Or suppose it’s Anya Taylor Joy’s birthday, and you want to create a highlight reel of all her most iconic and dramatic shots.
Creating these involves sifting through hundreds of thousands of movies and TV shows to find the right line of dialogue or the appropriate visual elements (objects, scenes, emotions, actions, etc.). We have built an internal system that allows someone to perform in-video search across the entire Netflix video catalog, and we’d like to share our experience in building this system.
Building in-video search
The Approach
We learned that contrastive learning works well for our objectives when applied to image and text pairs, as these models can effectively learn joint embedding spaces between the two modalities. This approach is also able to learn about objects, scenes, emotions, actions, and more in a single model. We also found that extending contrastive learning to videos and text provided a substantial improvement over frame-level models.
In order to train the model on internal training data (video clips with aligned text descriptions), we implemented a scalable version on Ray Train and switched to a more performant video decoding library. Lastly, the embeddings from the video encoder exhibit strong zero or few-shot performance on multiple video and content understanding tasks at Netflix and are used as a starting point in those applications.
The recent success of large-scale models that jointly train image and text embeddings has enabled new use cases around multimodal retrieval. These models are trained on large amounts of image-caption pairs via in-batch contrastive learning. For a (large) batch of N examples, we wish to maximize the embedding (cosine) similarity of the N correct image-text pairs, while minimizing the similarity of the other N²-N paired embeddings. This is done by treating the similarities as logits and minimizing the symmetric cross-entropy loss, which gives equal weighting to the two settings (treating the captions as labels to the images and vice versa).
Consider the following two images and captions:

Images are from Glass Onion: A Knives Out Mystery (2022)
Once properly trained, the embeddings for the corresponding images and text (i.e. captions) will be close to each other and farther away from unrelated pairs.

Typically embedding spaces are hundred/thousand dimensional.
At query time, the input text query can be mapped into this embedding space, and we can return the closest matching images.
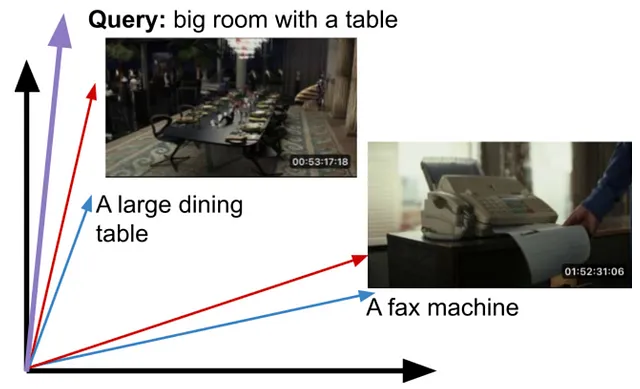
The query may have not existed in the training set. Cosine similarity can be used as a similarity measure.
While these models are trained on image-text pairs, we have found that they are an excellent starting point to learning representations of video units like shots and scenes. As videos are a sequence of images (frames), additional parameters may need to be introduced to compute embeddings for these video units, although we have found that for shorter units like shots, an unparameterized aggregation like averaging (mean-pooling) can be more effective. To train these parameters as well as fine-tune the pretrained image-text model weights, we leverage in-house datasets that pair shots of varying durations with rich textual descriptions of their content. This additional adaptation step improves performance by 15–25% on video retrieval tasks (given a text prompt), depending on the starting model used and metric evaluated.
On top of video retrieval, there are a wide variety of video clip classifiers within Netflix that are trained specifically to find a particular attribute (e.g. closeup shots, caution elements). Instead of training from scratch, we have found that using the shot-level embeddings can give us a significant head start, even beyond the baseline image-text models that they were built on top of.
Lastly, shot embeddings can also be used for video-to-video search, a particularly useful application in the context of trailer and promotional asset creation.
Engineering and Infrastructure
Our trained model gives us a text encoder and a video encoder. Video embeddings are precomputed on the shot level, stored in our media feature store, and replicated to an elastic search cluster for real-time nearest neighbor queries. Our media feature management system automatically triggers the video embedding computation whenever new video assets are added, ensuring that we can search through the latest video assets.
The embedding computation is based on a large neural network model and has to be run on GPUs for optimal throughput. However, shot segmentation from a full-length movie is CPU-intensive. To fully utilize the GPUs in the cloud environment, we first run shot segmentation in parallel on multi-core CPU machines, store the result shots in S3 object storage encoded in video formats such as mp4. During GPU computation, we stream mp4 video shots from S3 directly to the GPUs using a data loader that performs prefetching and preprocessing. This approach ensures that the GPUs are efficiently utilized during inference, thereby increasing the overall throughput and cost-efficiency of our system.
At query time, a user submits a text string representing what they want to search for. For visual search queries, we use the text encoder from the trained model to extract a text embedding, which is then used to perform appropriate nearest neighbor search. Users can also select a subset of shows to search over, or perform a catalog wide search, which we also support.
If you’re interested in more details, see our other post covering the Media Understanding Platform.
Conclusion
Finding a needle in a haystack is hard. We learned from talking to video creatives who make trailers and social media videos that being able to find needles was key, and a big pain point. The solution we described has been fruitful, works well in practice, and is relatively simple to maintain. Our search system allows our creatives to iterate faster, try more ideas, and make more engaging videos for our viewers to enjoy.
We hope this post has been interesting to you. If you are interested in working on problems like this, Netflix is always hiring great researchers, engineers and creators.